Quick Start Guide: Optimal Feature Selection for Regression
This is an R version of the corresponding OptimalFeatureSelection quick start guide.
In this example we will use Optimal Feature Selection on the Ailerons dataset, which addresses a control problem, namely flying a F16 aircraft. The attributes describe the status of the aeroplane, while the goal is to predict the control action on the ailerons of the aircraft.
First we load in the data and split into training and test datasets:
df <- read.table("ailerons.csv", header = TRUE, sep = ",")
climbRate Sgz p q curPitch curRoll absRoll diffClb diffRollRate
1 2 -56 -0.33 -0.09 0.9 0.2 -11 12 0.004
diffDiffClb SeTime1 SeTime2 SeTime3 SeTime4 SeTime5 SeTime6 SeTime7 SeTime8
1 -0.1 0.032 0.032 0.032 0.032 0.032 0.032 0.032 0.032
SeTime9 SeTime10 SeTime11 SeTime12 SeTime13 SeTime14 diffSeTime1 diffSeTime2
1 0.032 0.032 0.032 0.032 0.032 0.032 0 0
diffSeTime3 diffSeTime4 diffSeTime5 diffSeTime6 diffSeTime7 diffSeTime8
1 0 0 0 0 0 0
diffSeTime9 diffSeTime10 diffSeTime11 diffSeTime12 diffSeTime13 diffSeTime14
1 0 0 0 0 0 0
alpha Se goal
1 0.9 0.032 -9e-04
[ reached 'max' / getOption("max.print") -- omitted 13749 rows ]X <- df[, 1:40]
y <- df[, 41]
split <- iai::split_data("regression", X, y, seed = 1)
train_X <- split$train$X
train_y <- split$train$y
test_X <- split$test$X
test_y <- split$test$y
Model Fitting
We will use a grid_search to fit an optimal_feature_selection_regressor:
grid <- iai::grid_search(
iai::optimal_feature_selection_regressor(
random_seed = 1,
),
sparsity = 1:10,
)
iai::fit(grid, train_X, train_y)
Julia Object of type GridSearch{OptimalFeatureSelectionRegressor, IAIBase.NullGridResult, IAIBase.Data{IAIBase.RegressionTask, IAIBase.RegressionTarget}}.
All Grid Results:
Row │ sparsity train_score valid_score rank_valid_score
│ Int64 Float64 Float64 Int64
─────┼──────────────────────────────────────────────────────
1 │ 1 0.49788 0.475188 10
2 │ 2 0.663576 0.668303 9
3 │ 3 0.749368 0.752557 8
4 │ 4 0.807263 0.804385 7
5 │ 5 0.812985 0.808196 6
6 │ 6 0.816881 0.810463 5
7 │ 7 0.818946 0.813062 3
8 │ 8 0.818662 0.812035 4
9 │ 9 0.819254 0.813463 1
10 │ 10 0.819036 0.81332 2
Best Params:
sparsity => 9
Best Model - Fitted OptimalFeatureSelectionRegressor:
Constant: 0.000345753
Weights:
SeTime1: -0.00703259
SeTime2: -0.00948655
SeTime3: -0.00954495
Sgz: 0
absRoll: 0.0000576494
curRoll: -0.0000862381
diffClb: -0.00000279116
diffRollRate: 0.00253189
p: -0.000425322
The model selected a sparsity of 9 as the best parameter, but we observe that the validation scores are close for many of the parameters. We can use the results of the grid search to explore the tradeoff between the complexity of the regression and the quality of predictions:
plot(grid, type = "validation")
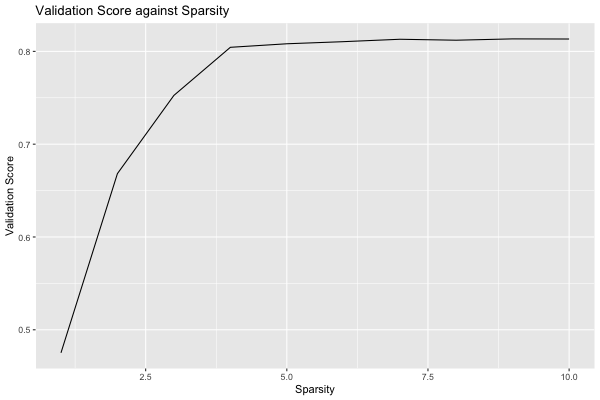
We see that the quality of the model quickly increases with additional terms until we reach 4, and then only small increases afterwards. Depending on the application, we might decide to choose a lower sparsity for the final model than the value chosen by the grid search.
We can see the relative importance of the selected features with variable_importance:
iai::variable_importance(iai::get_learner(grid))
Feature Importance
1 absRoll 0.34028240
2 p 0.18424729
3 curRoll 0.11924128
4 SeTime3 0.09415091
5 SeTime2 0.09357824
6 SeTime1 0.06906226
7 diffRollRate 0.04810879
8 diffClb 0.04111905
9 Sgz 0.01020978
10 Se 0.00000000
11 SeTime10 0.00000000
12 SeTime11 0.00000000
13 SeTime12 0.00000000
14 SeTime13 0.00000000
15 SeTime14 0.00000000
16 SeTime4 0.00000000
17 SeTime5 0.00000000
18 SeTime6 0.00000000
19 SeTime7 0.00000000
20 SeTime8 0.00000000
21 SeTime9 0.00000000
22 alpha 0.00000000
23 climbRate 0.00000000
24 curPitch 0.00000000
25 diffDiffClb 0.00000000
26 diffSeTime1 0.00000000
27 diffSeTime10 0.00000000
28 diffSeTime11 0.00000000
29 diffSeTime12 0.00000000
30 diffSeTime13 0.00000000
[ reached 'max' / getOption("max.print") -- omitted 10 rows ]We can also look at the feature importance across all sparsity levels:
plot(grid, type = "importance")
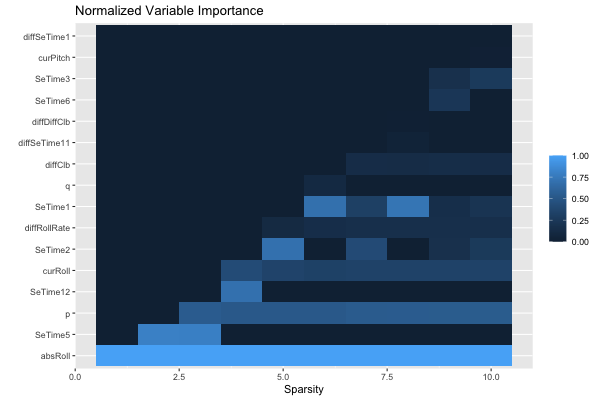
We can make predictions on new data using predict:
iai::predict(grid, test_X)
[1] -0.0010382838 -0.0012499715 -0.0012079392 -0.0008088259 -0.0011572235
[6] -0.0009776049 -0.0008290693 -0.0007732031 -0.0009328218 -0.0008354188
[11] -0.0007265183 -0.0009074517 -0.0010301476 -0.0009117926 -0.0008363757
[16] -0.0006847483 -0.0005530515 -0.0006042603 -0.0008956122 -0.0008568400
[21] -0.0005786814 -0.0009212146 -0.0008839955 -0.0005965527 -0.0008679341
[26] -0.0008895228 -0.0009010146 -0.0006680357 -0.0007944540 -0.0005956099
[31] -0.0007651949 -0.0008117134 -0.0008521886 -0.0006788704 -0.0008059922
[36] -0.0005789989 -0.0007499416 -0.0009831950 -0.0008080023 -0.0008854951
[41] -0.0008888135 -0.0005755793 -0.0007736011 -0.0006825822 -0.0007042730
[46] -0.0008589040 -0.0004992913 -0.0009465281 -0.0009067636 -0.0009856128
[51] -0.0010706208 -0.0008832450 -0.0006564582 -0.0007458934 -0.0010030714
[56] -0.0009736458 -0.0006985940 -0.0008771411 -0.0008830836 -0.0009855341
[ reached getOption("max.print") -- omitted 4065 entries ]We can evaluate the quality of the model using score with any of the supported loss functions. For example, the $R^2$ on the training set:
iai::score(grid, train_X, train_y, criterion = "mse")
[1] 0.8176296Or on the test set:
iai::score(grid, test_X, test_y, criterion = "mse")
[1] 0.8173307